
定义
顺序表是指线性表的顺序存储结构
主要有:顺序查找和二分查找
采用一维数组表示,元素类型为NodeType,它含有关键字key域和其它数据域data,key域的类型假定用标识符KeyType(int)表示
数据类型
typedef struct
{
KeyType key;
infoType data;
}NodeType;
typedef NodeType SeqList[n+1]; //0号单元用作哨兵
顺序查找
又称线性查找,是一种最简单和最基本的查找方法
基本思想:
从表的一端开始,顺序扫描线性表,依次把扫描到的记录关键字与给定的值k相比较,若某个记录的关键字等于k,则表明查找成功,返回该记录坐在下标;若直到所有记录都比较完,任未找到关键字与k相等的记录,则表明查找失败,返回0值
1.一般顺序查找算法
算法描述
int SeqSearch(SeqList R,KeyType k,int n)
{
//R[0]作为哨兵,用R[0].key==k作为循环下界的终结条件 作用类似直接插入排序的Temp
R[0].key=k; //设置哨兵
i=n; //从后向前扫描
while(R[i].key!=k)
i--;
return i; //返回其下标,若找不到,返回0
}
算法分析
-
①查找成功的情况:最好的情况比较1次,最坏的情况比较n次查找成功时的平均查找长度=
$$
(1+2+3+…+n)/n=\frac{(n + 1)}{2}
$$ -
②查找失败时的查找长度=(n+1)
-
③如果查找成功和不成功机会相等,顺序查找的平均查找长度为
$$
(\frac{\frac{(n+1)}{2}+(n+1)}{2})= \frac{3}{4}(n + 1)
$$
2.在递增有序的顺序表的查找算法
算法描述
int SeqSearchl(SeqList R,KeyType k,int n) //有序表的顺序查找算法
{
int i=n; //从后向前扫描,表按递增排序
while(R[i].key>k)
i--; //循环结束时,要么R[i].key=k,要么R[i].key<k
if(R[i].key==k)
return i; //找到,返回其下标
return 0; //没找到,返回0
}
算法分析
-
①查找成功的平均查找长度=
$$
\frac{(n + 1)}{2}
$$ -
②查找失败的平均查找长度=
$$
\frac{(n + 1)}{2}
$$ -
③如果查找成功和不成功机会相等,该算法的平均杳找长度为=
$$
(\frac{(n + 1)}{2} + \frac{(n + 1)}{2}) \frac{1}{2} = \frac{(n + 1)}{2}
$$
二分查找
对有序表可以用查找效率较高的二分查找方法来实现查找运算。
表是有序的
思想
首先将待查的k值和有序表R[1...n]的中间位置mid上的记录的关键字进行比较,若相等,则查找成功,返回该记录的下标mid;否则,若R[mid].key>k,则k在左子表R[1...mid-1]中,接着再在左子表中进行二分查找即可﹔否则,若R[mid].key< k,则说明待查记录在右子表R[mid+1...n]中,接着只要在右子表中进行二分查找即可。这样,经过一次关键字的比较,就可缩小一半的查找空间,如此进行下去,直到找到关键字为k的记录或者当前查找区间为空时(即查找失败)为止。二分查找的过程是递归的。
实例分析
对有序表(13,25,36,42,48,56,64,69,78,85,92)用二分查找法查找42和80,所需的比较次数依次为()
A.1次和2次
B.2次和3次
C.3次和2次
D.3次和3次
解答
【答案】D
【解析】按二分查找的基本思想给出查找42的过程知下
设置三个指针:low表示最左边(表头),mid表示中间值(用于作为分割线,左边的值比他小,右边的值比他大),high表示最右边(表尾)
每次都跟mid比较用于确定范围


算法描述
(1)二分查找递归算法
int BinSearch(SeqList R,KeyType k,int low,int high)
{
//在区间R[low....high]内进行二分递归,查找关键字值等于k的记录
//1ow的初始值为1,high的初始值为n
int mid;
if(low<=high)
{
mid=(lowthigh)/ 2;
if(R[mi d].key==k) return mid; //查找成功,返回其下标
if(R[mid].key>k)
return BinSearch(R,k,low,mid-1); //在左子表中继续查找
else
return Binsearch(R,k,mi d+1,high); //在右子表中继续查找
}
else
return 0;
}
(2)二分查找非递归算法
int BinSearch(SeqLiSt R, KeyType k, int n) //初始化上下界
{
int low=1,mid, high=n;
while(low<=high) {
mid=(lowthigh)/ 2;
if(R[mid].key==k)
return mid; //查找成功,返回其下标
if(R[mi d].key>k)
high=mid-1; //修改上界
else
low=mid+1; //修改下界
}
return 0; //查找失败,返回0值
}
算法分析
二分查找方法可以用一棵判定树描述,查找任一元素的过程对应该树中从根结点到相应结点的一条路径。最短的查找长度为1,最长的查找长度为对应判定树的深度[log2n]+1,平均查找长度为:
$$
\frac{(n+1)}log_2(n+1)-1 ≈ log_2(n+1)-1
$$
。二分查找方法效率高是有代价的,因为有序表是通过排序而得到的,而排序操作又是比较费时的。二分查找只适用于顺序结构上的有序表,对链式结构无法进行二分查找。
二分查找的最坏性能和平均性能相当接近
n个结点的判定树深度和n个结点的完全二叉树深度相同
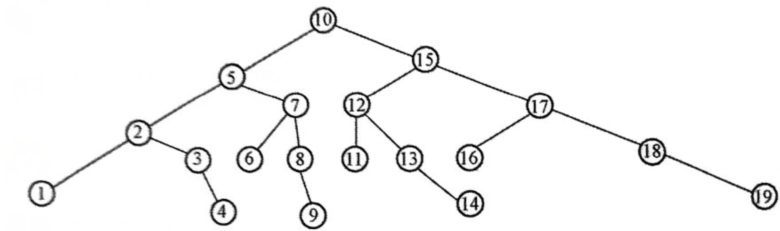
例
对19个记录的有序表进行二分查找,试画出描述二分查找过程的二叉树,并计算在每个记录的查找概率相同的情况下的平均查找长度
解答
二分查找过程的二叉树如下
在二叉树判定树上表示的结点所在层数(深度)就是查找结点所需要比较的次数,平均长度(平均比较次数):
ASL = (1 + 2 * 2 + 3 * 4 + 4 * 8 + 5 * 4) / 19 = 69 / 19 ≈ 3.42
索引顺序查找
又称分块查找。
它是一种性能介于顺序查找和二分查找之间的查找方法。
索引查找表的存储结构
(1)"分块有序"的线性表
将表R[1...n]均分为b块,前b-1块中结点个数为 s=[n/b],第b块的结点数≤s;每一块中的关键字不一定有序,但前一块中的最大关键字必须小于后一块中的最小关键字,即表是"分块有序”的。
(2)索引表
抽取各块中的最大关键字及其起始位置构成一个索引表ID[1...b],即: ID[i](1≤i≤1)中存放第i块的最大关键字及该块在表R中的起始位置。由于表R是分块有序的,所以索引表是—个递增有序表。
索引表是按关键字递增有序
索引查找的基本思想
(1)首先查找索引表
索引表是有序表,可采用二分查找或顺序查找,以确定待查的结点在哪一块。
(2)然后在已确定的块中进行顺序查找
由于块内无序,只能用顺序查找。
由于分块查找实际上是两次查找过程,因此整个查找过程的平均查找长度,是两次查找的平均查找长度之和
索引查找的平均查找长度
(1)二分查找
查找索引表采用二分查找时的平均查找长度:
ASLblk=log2 (b+1) -1+ (s+1)/2 ≈ log2 (n/s+1)+s/2
(2)顺序查找
查找索引表采用顺序查找时的平均查找长度:
ASLblk=(b+1)/2+(s+1)/2= (b+s)/2+1= (n/s+s)/2+1 =(块数+块长)/2+1
当s取 $ \sqrt $ (即s=b)时,ASLb1k达到最小值 $ \sqrt + 1 $,
即当采用顺序查确定块时,应将各块中的结点数选定为$ \sqrt $
三种查求方法比较
1.顺序查找
优点: 算法简单,对表的存储结构无任何要求。
缺点: 查找效率低,查找成功的平均查找长度为(n+1)/2,查找失败的查找长度为(n+1)。
2.二分查找
优点: 二分查找的速度快,效率高,查找成功的平均查找长度约为log2(n+1)-l。
缺点: 要求表以顺序存储表示并且是按关键字有序,使用高效率的排序方法也要花费O(nlog2n)的时间。另外,当对表结点进行插入或册除时,需要移动大量的元素,所以二分查找适用于表不易变动且又经常查找的情况。
3.分块查找
优点: 在表中插入或删除一个记录时,只要找到该记录所属的块,就可以在该块内进行插入或删除运算。因为块内记录是无序的,所以插入或删除比较容易,无需移动大量记录。
缺点: 是需要增加一个辅助数组的存储空间和将初始表块排序的运算,它也不适宜用链式存储结构。
若以二分查找确定块,则分块查找成功的平均查找长度未log2(n/s+1)+s/2
若以顺序表查找确定块,则分块查找成功的平均查找长度为(s2 +2s+n)/(2s)
其中s为分块中的结点个数
此外,顺序查找、二分查找和分块查找三种查找算法的时间复杂度分别为:O(n)、O(1og2n)和O($ \sqrt $)。分块查找算法的效率介于顺序查找和二分查找之间。
例
